机器学习笔记-非线性转换
笔记整理自台大林轩田老师的开放课程-机器学习基石,笔记中所有图片来自于课堂讲义。
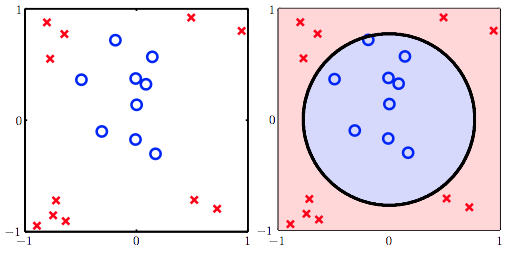
前面的笔记所谈到的分类模型,都是基于线性的,即我们假设数据是线性可分,或者至少看起来用一条线来做分类是不错的。但现实中我们的数据往往不那么容易得能用一条线区分开来。
笔记整理自台大林轩田老师的开放课程-机器学习基石,笔记中所有图片来自于课堂讲义。
前面的笔记所谈到的分类模型,都是基于线性的,即我们假设数据是线性可分,或者至少看起来用一条线来做分类是不错的。但现实中我们的数据往往不那么容易得能用一条线区分开来。
笔记整理自台大林轩田老师的开放课程-机器学习基石,笔记中所有图片来自于课堂讲义。
前面的笔记介绍了三种线性模型,PLA、Linear Regression与Logistic Regression。之所以称他们是线性模型,是因为这三种分类模型的方程中,都含有一个相同的部分,该部分是各个特征的一个线性组合,也可以称这个部分叫做线性评分方程:
$$\color{purple}{s}=w^Tx$$

笔记整理自台大林轩田老师的开放课程-机器学习基石,笔记中所有图片来自于课堂讲义。
上一篇比较深入地去理解了线性回归的思想和算法。分类和回归是机器学习中很重要的两大内容。而本篇要讲的Logistic Regression,名字上看是回归,但实际上却又和分类有关。
之前提过的二元分类器如PLA,其目标函数为, $f(x)=sign(w^Tx)\in{-1,+1}$,输出要么是-1要么是+1,是一个“硬”的分类器。而Logistic Regression是一个“软”的分类器,它的输出是$y=+1$的概率,因此Logistic Regression的目标函数是 $\color{purple}{f}(x)=\color{orange}{P(+1|x)}\in [0,1]$。
最近阿里巴巴办了个数据挖掘竞赛-阿里巴巴大数据竞赛,题目是根据天猫用户4个月的行为记录来预测用户下一个月会买什么东西,参赛对象为高校在校学生。由于奖金数额十分巨大,因此比赛规模可以说是空前绝后的,短短2周就有4000多支队伍报名。比赛过程中,每队每周可以提交一次结果,组委会每周日统一计算各队的分数并公布排行榜(top 500)。
噢,忘了说了这篇文章是关于R语言抓数据以及画图的,与比赛木有关系。本篇的内容纯粹just for fun,不具任何实际价值。是对我最近在cos.name上混来的一些R语言技巧的复习。
笔记整理自台大林轩田老师的开放课程-机器学习基石,笔记中所有图片来自于课堂讲义。
向所有坚持用$\LaTeX$手打公式而不是直接使用截图的偏执狂致敬!
原计划此篇应该要整理机器学习笔记-VC Dimension, Part II,但动笔整理之后才发现,其实自己果真没有理解得太透彻,以至于把林老师的视频和讲义看了好几遍,只能到不明觉厉的地步,但见武功招式,却还无法深入其内功心法。所以希望还是能多磨一些时日,争取把它搞懂。