笔记整理自台大林轩田老师的开放课程-机器学习基石,笔记中所有图片来自于课堂讲义。
上一篇讲到了VC Dimension以及VC Bound。VC Bound所描述的是在给定数据量N以及给定的Hypothesis Set的条件下,遇到坏事情的概率的上界,即与差很远的概率,最多是多少。VC Bound用公式表示就是:
其中为Hypothesis Set的成长函数,有:
因为寻找所有Hypothesis Set的成长函数是困难的,因此我们再利用来bound住所有VC Dimension为的Hypothesis Set的成长函数。所以对于任意一个从中的来说,有:
因此说想让机器真正学到东西,并且学得好,有三个条件:
- 的是有限的,这样VC Bound才存在。(good )
- 足够大(对于特定的),这样才能保证上面不等式的bound不会太大。(good )
- 算法有办法在中顺利地挑选一个使得最小的方程。(good )
为什么要费那么大的力气来讲这个VC Bound和VC Dimension呢?因为对于初学者来说,最常犯的错误就是只考虑到了第3点,而忽略掉了前两点,往往能在training set上得到极好的表现,但是在test set中表现却很烂。关于算法的部分会在后续的笔记当中整理,目前我们只关心前面两点。
几种Hypothesis Set的VC Dimension
对于以下几个,由于之前我们已经知道了他们的成长函数(见机器学习笔记-VC Dimension, Part I),因此可以根据,直接得到他们的VC Dimension:
- positive rays: ,看N的最高次项的次数,知道
- positive intervals: ,
- convex sets: ,
- 2D Perceptrons: ,所以
由于convex sets的,不满足上面所说的第1个条件,因此不能用convex sets这个来学习。
但这里要回归本意,通过成长函数来求得没有太大的意义,引入很大的一部分原因是,我们想要得到某个Hypothesis Set的成长函数是困难的,希望用来bound住对应的。对于陌生的,如何求解它的呢?
某个的VC Dimension - 从"shatter"的角度
Homework当中的某题,求解简化版决策树的VC Dimension:
Consider the simplified decision trees hypothesis set on , which is given by
That is, each hypothesis makes a prediction by first using the thresholds to locate to be within one of the hyper-rectangular regions, and looking up to decide whether the region should be +1 or −1. What is the VC-dimension of the simplified decision trees hypothesis set?
如何去理解题意呢?用一个2维的图来帮助理解:
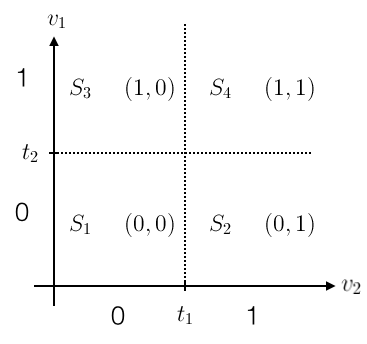
首先把二维实数空间中的向量,通过各个维度上的阈值,转换到空间下的一个点,规则为。譬如对于,可以转换为新的空间下的。这样一来,原来的空间就可以被划分为4个区块~(hyper-rectangular regions)。中每一个方程代表着一种对这4块区域是”圈圈“还是”叉叉“的决策(decision),并且这4块区域的决策是互相独立的,的决策是”圈圈“还是”叉叉“和都没有关系。
由于这4块区域的决策是互相独立的,那么它最多最多能shatter掉多少个点呢?4个,(当这4个点分别属于这4块区域的时候),即这4块hyper-rectangular regions所代表的类别可以是(o,o,o,o)、(o,o,o,x)、(o,o,x,o)、...、(x,x,x,x),共16种可能,因此它能够shatter掉4个点。
由上面2维的例子我们可以看出,simplified decision trees的VC Dimension,等于hyper-rectangular regions的个数。维空间可以用条直线切分出个互相独立的hyper-rectangular regions,即最多最多可以shatter掉个点,因此simplified decision trees的。
我们再来回顾一下Positive Intervals:

也可以按照上面的方法去理解,Positive Intervals有两个thresholds,把直线切分为3块空间。但这3块空间并不是相互独立,中间的部分永远是+1,左右两边永远是-1,所以还要具体看它能够shatter掉多少个点,这里最多最多只能shatter掉2个点,它的。
某个的VC Dimension - 从"自由度"的角度
对于较小的,可以从它最多能够shatter的点的数量,得到,但对于一些较为复杂的模型,寻找能够shatter掉的点的数量,就不太容易了。此时我们可以通过模型的自由度,来近似的得到模型的。
维基百科上有不止一个关于自由度的定义,每种定义站在的角度不同。在这里,我们定义自由度是,模型当中可以自由变动的参数的个数,即我们的机器需要通过学习来决定模型参数的个数。
譬如:
- Positive Rays,需要确定1个threshold,这个threshold就是机器需要根据来确定的一个参数,则Positive Rays中自由的参数个数为1,
- Positive Intervals,需要确定左右2个thresholds,则可以由机器自由决定的参数的个数为2,
- d-D Perceptrons,维的感知机,可以由机器通过学习自由决定的参数的个数为(别忘了还有个),
多个的并集的VC Dimension
Homework当中某题,求个Hypothesis Set的并集的VC Dimension的上下界。下界比较好判断,是,即所有的都包含于最大的那个当中的时候。上界则出现在各个互相都没有交集的时候,我们不妨先来看看的情况:
求的上界,已知,。
从成长函数上看,有 ,把成长函数展开,有
用替换RHS,有
我们可以尝试寻找下上面这个成长函数有可能的最大的break point,让不断增大,直到出现的时候,这个就是break point。那么要多大才够呢?
够大吗?不够,因为:
够大吗?还是不够,因为:
够大吗?够大了,因为:
所以的break point最大可以是,此时。
因此两个的并集的VC Dimension的上界为。利用此方法,就很容易可以推出个的并集的情况。
简单 v.s 复杂
机器学习笔记-VC Dimension, Part I一开始就提到,learning的问题应该关注的两个最重要的问题是:1.能不能使与很接近,2.能不能使足够小。
- 对于相同的而言,小的模型,其VC Bound比较小,比较容易保证与很接近,但较难做到小的,试想,对于2D Perceptron,如果规定它一定要过原点(),则它就比没有规定要过原点()的直线更难实现小的,因为可选的方程更少。2维平面的直线,就比双曲线(),更难实现小的。
- 对于相同的而言,大的模型,比较容易实现小的,但是其VC Bound就会很大,很难保证模型对之外的世界也能有同样强的预测能力。
令之前得到的VC Bound为,坏事情发生的概率小于,则好事情发生的概率就大于,这个在统计学中又被称为置信度,或信心水准。
因此、又有下面的关系:
令,即上式的根号项为来自模型复杂度的,模型越复杂,与离得越远。
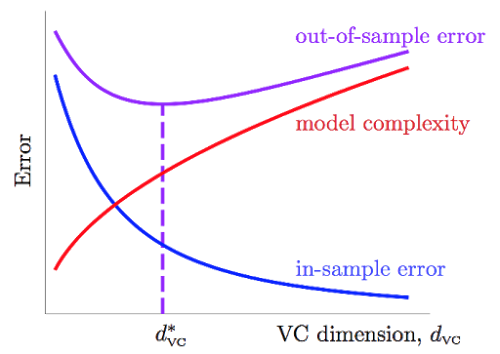
随着的上升,不断降低,而项不断上升,他们的上升与下降的速度在每个阶段都是不同的,因此我们能够寻找一个二者兼顾的,比较合适的,用来决定应该使用多复杂的模型。
反过来,如果我们需要使用这种复杂程度的模型,并且想保证,置信度,我们也可以通过VC Bound来求得大致需要的数据量。通过简单的计算可以得到理论上,我们需要笔数据,但VC Bound事实上是一个极为宽松的bound,因为它对于任何演算法,任何分布的数据,任何目标函数都成立,所以经验上,常常认为就可以有不错的结果。