前面花了很大篇幅在说机器为何能学习,接下来要说的是机器是怎么学习的,进入算法的部分。上一篇稍微提到了几个error的衡量方式,接下来的几篇笔记要讲的就是各种error measurement的区别以及针对它们如何设计最优化的算法。通过设计出来的算法,使得机器能够从(Hypothesis Set)当中挑选可以使得cost function最小的作为输出。
本篇以众所周知的线性回归为例,从方程的形式、误差的衡量方式、如何最小化的角度出发,并简单分析了Hat Matrix的性质与几何意义,希望对线性回归这一简单的模型有个更加深刻的理解。
方程的形式:
长得很像perceptron(都是直线嘛),perceptron是。
误差的衡量 — 平方误差(squared error):
Cost function:
是一个以为变量的方程,而变成了一个以为变量的方程。这样一来,我们就把“在中寻找能使平均误差最小的方程”这个问题,转换为“求解一个函数的最小值”的问题。使得最小的,就是我们要寻找的那个最优方程的参数。
如何最小化:
用矩阵形式表示:
与来源于,是固定不变的,因此它是一个以为变量的函数。我们需要解使得最小的,即。这个是一个连续(continuous)、处处可微(differentiable)的凸函数(convex):
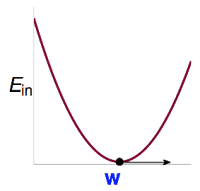
对于这一类函数,只需要解其一阶导数为0时的解即可。
关于多元函数的求导,就是线性代数的范畴了:
所以有:
令,可得最佳解:
当可逆的时候用它作为pseudo-inverse矩阵,当不可逆的时候,再用其他方式定义,这里就不详述了。
用以为参数的线性方程对原始数据做预测,可以得到拟合值。这里又称为Hat Matrix,帽子矩阵,为带上了帽子,成为,很形象吧。
Hat Matrix 的几何意义
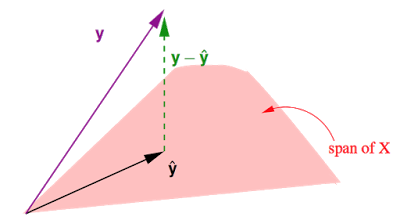
这张图展示的是在N维实数空间中,注意这里是N=数据笔数,中包含所有真实值,中包含所有预测值,与之前讲的输入空间是d+1维是不一样的噢。中包含d+1个column:
- 是的一个线性组合,中每个column对应下的一个向量,共有d+1个这样的向量,因此在这d+1个向量所构成的(平面)上。
- 事实上我们要做的就是在这个平面上找到一个向量使得他与真实值之间的距离最短。不难发现当是在这个平面上的投影时,即时,最短。
- 所以之前说过的Hat Matrix ,为戴上帽子,所做的就是投影这个动作,寻找上的投影。
- ,。(为单位矩阵)
下面来探究一下的性质,这个很重要噢。
- 对称性(symetric),即:
- 幂等性(idempotent),即:
- 半正定(positive semi-definite),即所有特征值为非负数:
(以下为特征值,为对应的特征向量)
林老师在课堂上讲到:
为矩阵的迹。这条性质很重要,但是为什么呢?证明过程有点多,以后有机会再补充,心急的同学可以看这里[General formulas for bias and variance in OLS][4]。一个矩阵的等于该矩阵的所有特征值(Eigenvalues)之和。
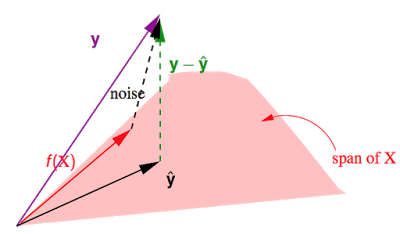
假设由构成的。有。之前讲到作用于某个向量,会得到该向量在上的投影,而作用于某个向量,会得到那条与垂直的向量,在这里就是图中的,即。
这个是真实值与预测值的差,其长度就是就是所有点的平方误差之和。于是就有:
上面的证明不太好整理进来,依然可以参考General formulas for bias and variance in OLS。
因此,就平均而言,有:
花这么大力气是为了什么,又回到之前learning可行性的话题了。
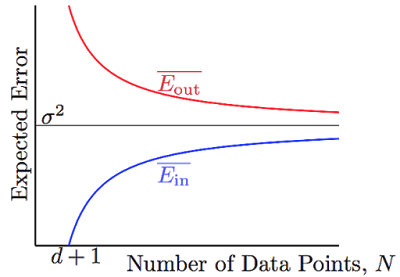
和都向(noise level)收敛,并且他们之间的差异被给bound住了。有那么点像VC bound,不过要比VC bound来的更严格一些。